
|
|
Background
Since the beginning of our development, we have been making extensive use of Apache Beam, a unified programming model for batch and stream processing. Back then, the reasoning behind it was simple:
We all knew Java and Python well, needed a solid stream processing framework, and were pretty certain that we would need batch jobs at some point in the future. Also, we appreciated Beam’s portability efforts, allowing us to run it on Google Cloud Dataflow, Apache Flink, Apache Spark, and many more.
Fast forward to today and we are running our main ingestion pipeline on Apache Beam’s Java SDK and haven’t looked back. What I especially like about the Java SDK is how seamless Protobuf, the serialization protocol of our choice, integrates into Beam: As exemplified below, we parametrize a DoFn with an InputType and OutputType, allowing us to directly access the language native Protobuf container class – no need to handle deserialization on your own!
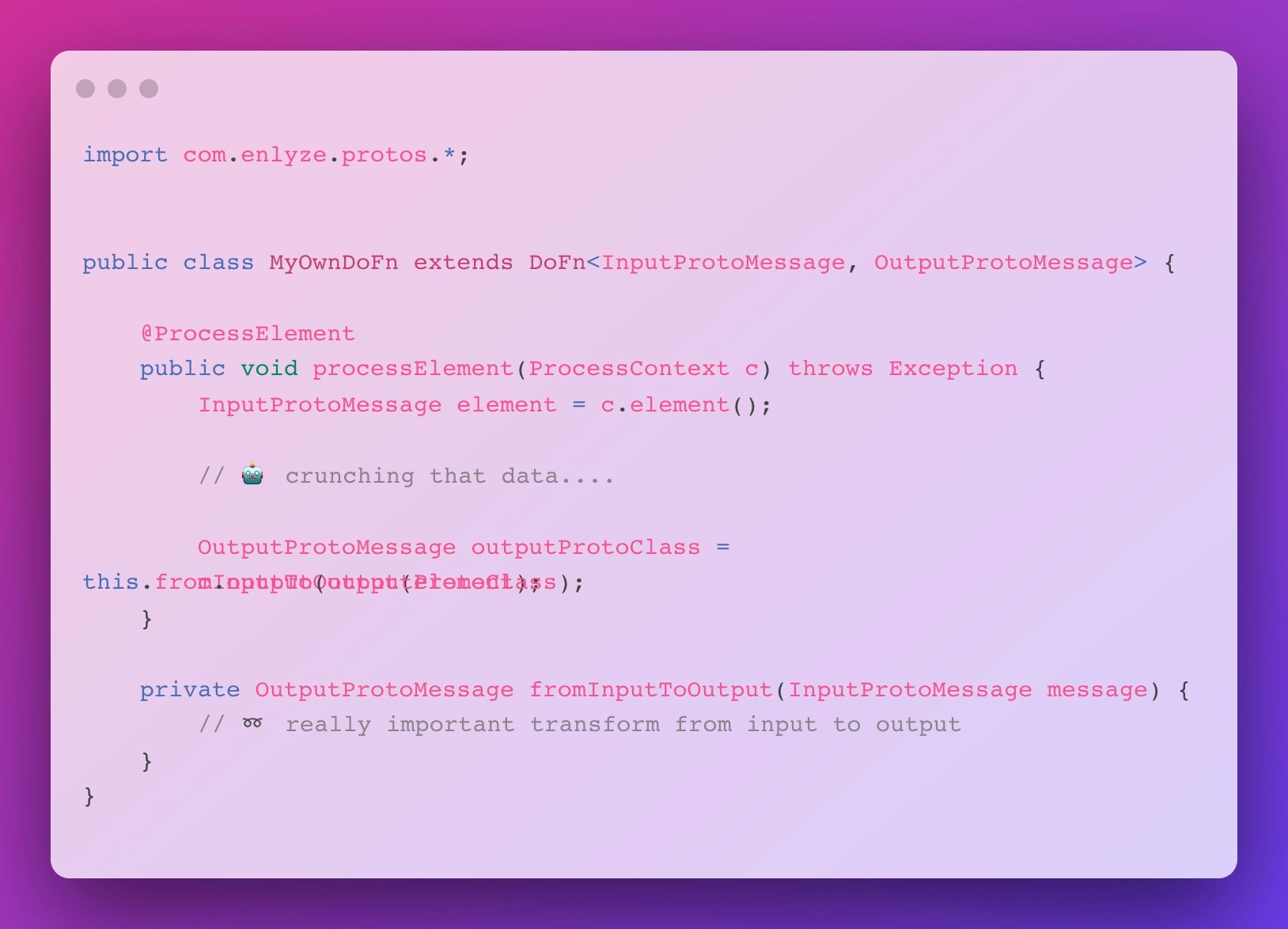
Also, note that we are passing in an argument of type OutputProtoMessage into c.output() and serialization is handled by Beam under the hood. I really like this abstraction, as it helps you to cut through the noise and lets you focus on the actual computation you would like to perform on the data.
At some point, you tend to forget that the code you’re writing may be executed in parallel across an arbitrary number of threads and machines, which in my opinion is one of the clear strengths of Apache Beam.
The Python Way of Things
However, this looks vastly different for the Beam Python SDK: As of right now, there seems to be no baked-in or go-to solution when it comes to mimicking the functionality described above. After quickly browsing through Stackoverflow, people seem to have come up with various workarounds such as (mis)using TfRecords [1] or building transforms, which deserialize Protobuf messages and return Python dicts [2].
This may be me being biased, but I especially find the latter solution problematic: It encourages ditching any strict protocol declaration for good and simply pass arbitrary data structures through the pipeline, which is just asking for trouble.
If asked to do this quick ‘n’ dirty, I would have opted into manual (de)serialization in every DoFns process method, leading to ever-repeated code along the lines of the code block below.
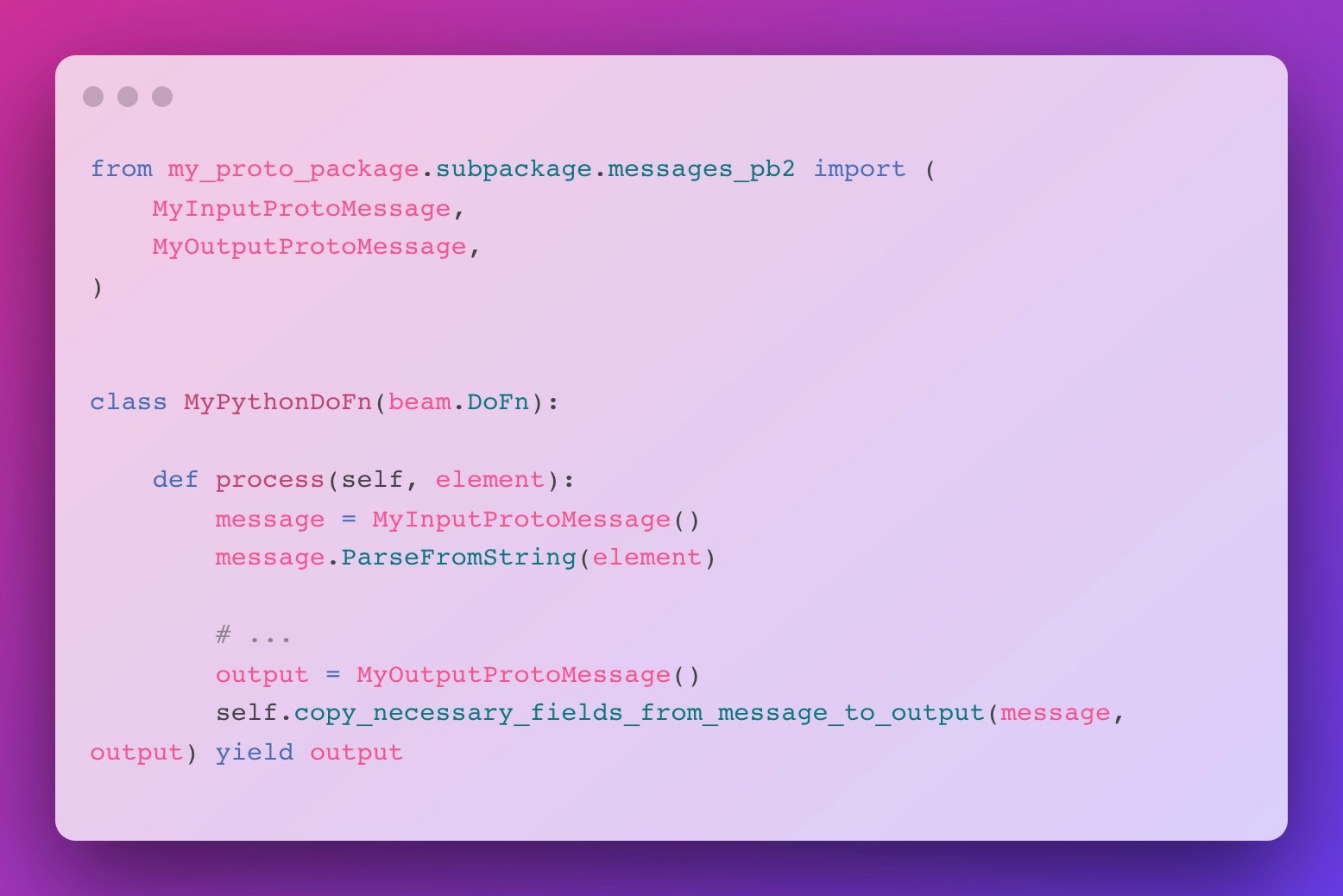
Funny enough, this approach already gives us a hint towards a potential way out of this dilemma, as it seems like the actual computation of any DoFn dealing with Protobuf messages seems to be enclosed by the very same logic:
Deserialize → Compute → Serialize
If you are near as OCD as our team when it comes to unnecessarily bloated code, this won’t let you sleep at night until you find a more elegant solution. Look no further! Stay tuned and learn how to achieve a similar look and feel as the Java SDK for your Python Beam pipeline using decorators 💥!
Decorators To the Rescue
Generally speaking, Python decorators are higher-order functions, which extend the behaviour of its input function without modifying it [3]. More, while decorators may be used to implement the Decorator pattern, they can be used for more powerful shared logic [4].
So let’s get our hands dirty, shall we? First, we will implement a decorator, which will take care of serializing Protobuf messages after we yield them in our process method. Based on this, I will lay out the basic structure of decorators in Python before moving on to the trickier part of deserialization.
Serializing Protobuf Messages
From an API standpoint, the process of serializing Protobuf messages is consistent across different message types and even Protobuf versions: Simply call the SerializeToString() method and there it is – the byte-string representation of your message. This makes implementing a decorator for this fairly straightforward:
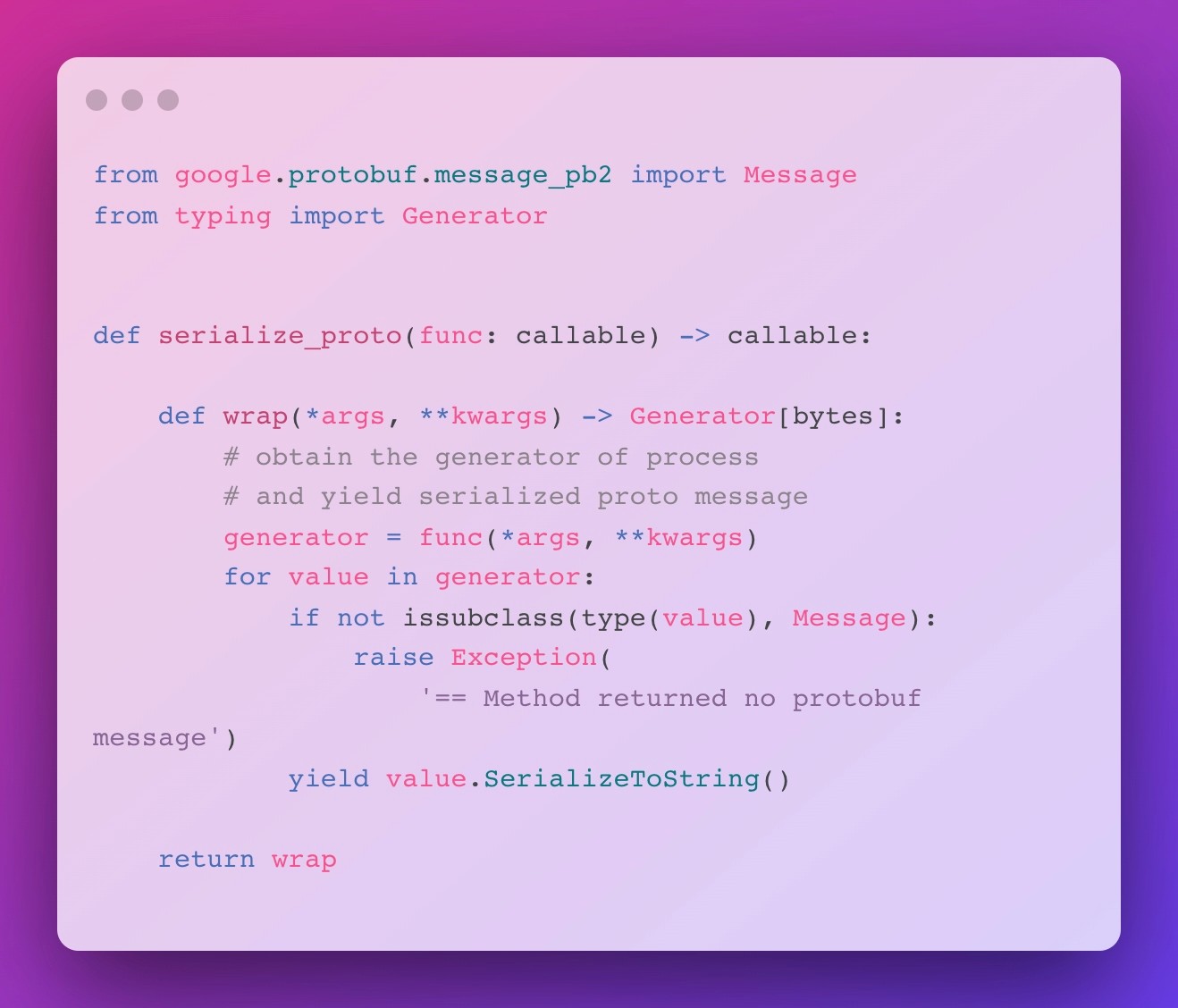
Let me walk you through the code, just in case you haven’t seen an actual implementation of a decorator yet: As you can see, we define a higher-order function (identified by taking in another function as its argument) named serialize_proto, which returns a function named wrap.
Inside wrap, we call the function passed into serialize_proto with the args and kwargs of wrap. This function – func in our example – represents the original process method of a beam.DoFn. But there’s a catch specific to process methods in DoFns: they don’t return – they yield.
This statement is specific to a special type of functions in Python named generator functions, which have the peculiarity to produce potentially multiple output values over time [5]. From an implementation perspective, handling generator functions inPpython is quite easy: When called, they return an iterator, which can be traversed in a loop.
In our case, we simply check whether the produced value is a valid Protobuf message class instance and then call SerializeToString() on it. Finally, we yield the serialized result, mimicking the behaviour of the original process method.
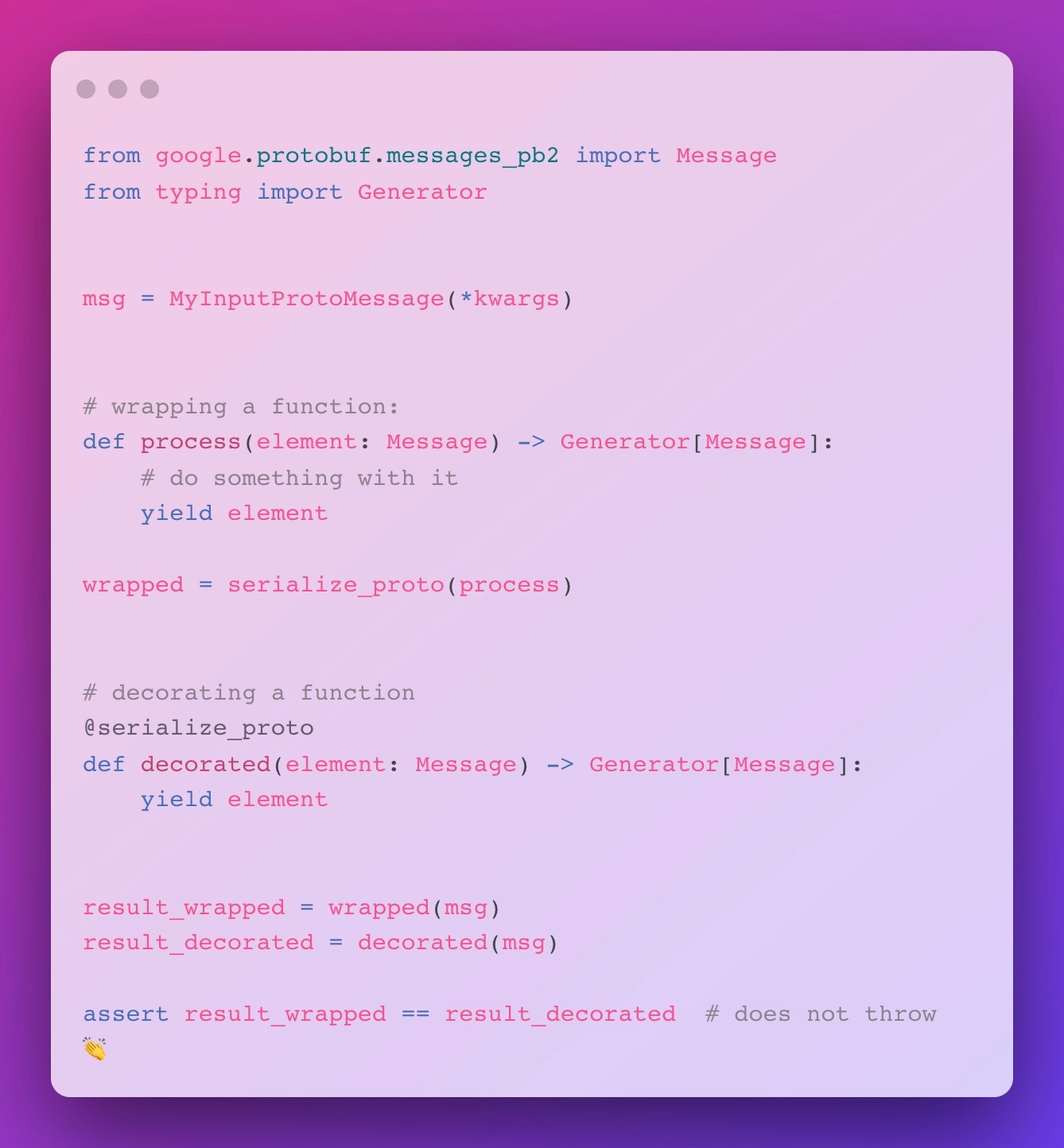
“But how do I use this?” - you might ask. Actually, there are two ways to achieve this, which are presented in the code block below: Either by decorating or wrapping any function returning a Protobuf message with serialize_proto. Note that this is merely a different syntax – both work the very same way.
Deserializing Protobuf Messages
When it comes to deserializing Protobuf messages, it gets a bit more complicated: In contrast to the serialization, we don’t have a uniform process, where calling SerializeToString() does the job. Rather, we need to first create an instance of the correct Protobuf message class and then call ParseFromString() on it. It is straightforward to see how this may vary from transform to transform and writing one decorator for each transform is obviously not the way to go.
Luckily, decorators are nothing more than plain Python functions, so that with minor extension of our code, we can pass arguments into them. Building up on this, we can use that to specify the expected Protobuf Message class as shown in the code block below.

And this already is the implementation of the entire decorator. To put this into action, simply decorate your transform’s process method with the proto_coder, specifying the expected input Protobuf message class as an argument and you won’t be writing (de)serialization boilerplate in your Beam pipelines ever again:

Summary
In this post, we learned how we can leverage Python decorators to abstract away any (de)serialization code from our pipeline transforms within Apache Beam’s Python SDK and focus on the computations we want to perform. While multiple alternative implementations exist, I prefer this one as it keeps the type declaration as close to the actual variables as possible and lets you quickly infer, which Protobuf message you expect as input.
